
Author Identification using Naive Bayes Algorithm — Data Collection
Written: 01 Jan 2021 by Vinayak Nayak 🏷 ["machine learning"]This post is the first in a three part series which aims to implement a Machine Learning Algorithm in an end to end manner using dockers. The underlying objective of this problem is to build a classifier using Naive Bayes Algorithm which could tell if a sentence is more likely to have been uttered by Steve Rogers aka Captain America or Tony Stark aka Iron Man. I will be using both the names of both characters to suit the context through the remainder of this post and subsequent ones.
Note: Some websites do not allow for scraping of data. Please ensure that you are aware of the terms and conditions of a website before proceeding with any form of data scraping. The following is for educational purposes only.

Motivation
The Naive Bayes algorithm is a really powerful algorithm for establishing a strong baseline for a classification problem. It really deserves more attention than it gets in the real world. It could be used in multiple problems like Author Identification, Information Retrieval, Word Disambiguation apart from the usual Spam Filtering and Sentiment Analysis which is what most people think Naive Bayes is limited to.
In this series of posts, I want to go through this algorithm in detail and build an end to end machine learning solution using Naive Bayes. It would cover the following steps in detail:
-
Data Collection and Pre-processing.
-
Model Building and Inference.
-
Deploying the model through an API endpoint using Flask, Flasgger.
-
Containerising the web app using Docker and deploying it to Heroku.
In this post, we shall discuss how we could scrape the web for getting data and also pre-process it to get it into a form that suits a supervised classification problem.
Data Collection & Preprocessing
In order to build a classifier that could distinguish the dialogues of Steve Rogers from Tony Stark, we need a good amount of dialogues which both of them have spoken. In order to do that we will have to resort to web-scraping for extracting these dialogues from freely available transcripts from the web.
This is how we will prepare our data:
-
For obtaining a corpus of Captain America’s dialogues, we will scrape the sentences uttered by Captain in the transcript of the movie “Captain America: The First Avenger”.
-
To build a corpus of Iron Man’s dialogues, we shall extract sentences spoken by Tony Stark in the transcript of the movie “Iron Man”.
-
The above will serve as our training dataset; To evaluate the performance of our model, we shall extract both Captain and Tony’s dialogues from “Avengers: Endgame”.
We will use the requests library to extract the html source from the webpages of transcripts and beautifulsoup to parse the html for extracting dialogues. Let’s see how it’s done.
First, we shall extract Steve Rogers’ dialogues from Captain America: The First Avenger using the transcript from fandom’s website.
First use the get method from the requests library for extracting the html source code; next parse the entire page using html parser with BeautifulSoup4 library. Once we’re through this, we need to figure out the tag of interest which hosts all the dialogues. If you’re working with Chrome, you can open the website and press Ctrl/Command + Shift + I to inspect elements from that page’s html DOM tree. Then click on the inspect button and move your mouse to the area of dialogue on the main page.
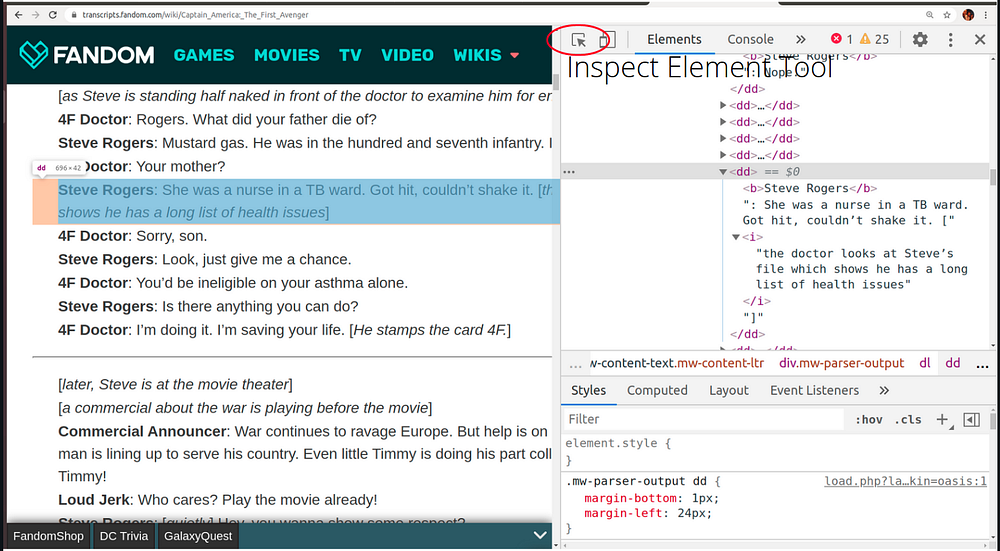
We can see from the above snippet that the dialogues are all wrapped up in the <dd> tag and the narrator is always highlighted in bold. So, we shall use this information as follows.
-
First we shall extract all the
<dd>tags and store them in a list. We shall use the find_all method for this purpose. -
Next we will extract the
<b>tag from these<dd>tags individually and look at the text content in these tags. Note that the colon is sometimes inside the bold tag and sometimes it is not. So what we will do is only pick the content of those<dd>tags which have “Steve Rogers” or “Steve Rogers:” in their respective bold tags.
Also note that we are only interested in the actual dialogue and not the actions/scene info etc. which is encapsulated in square brackets. So we will use a regular expression to replace the content in those brackets (including the brackets) with an empty string.
Similarly, we need to replace the narrator text i.e. “Steve Rogers:” from the text which could be simply done using the replace function inherently available to every string variable.
We can iterate this same procedure for Iron Man and Avengers:Endgame to obtain the dialogues for both Cap and Tony respectively. Note that you’ll have to inspect the element for the two web-pages separately and look at the nuances therein for eg. in the Iron Man script, all the dialogues are bound in the <p> tag. Also, in Avengers:EndGame script, the names of narrators are capitalized, this means that we will have to look for “STEVE ROGERS” instead of “Steve Rogers” in the bold tag for tagging the dialogue.
Once we’re done getting the list of dialogues we can then create a dataframe of dialogues and their respective narrator/speaker for both training and inference.
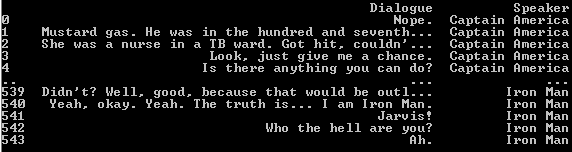
In the training dataset, we have 544 dialogues and in the test dataset we have 270 dialogues. This is expected since the test dataset contains dialogues only from one film i.e. Avengers:Endgame as against the train dataset which has dialogues from two films. The distribution of dialogues in both the dataset is as follows.
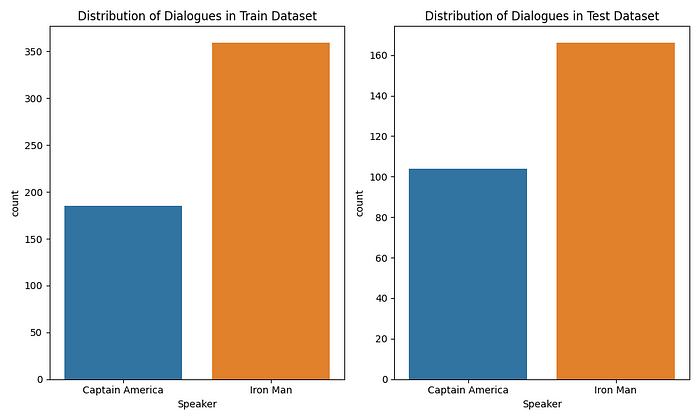
It could be seen that both the train and test datasets have nearly similar distributions of the two classes; which is always a good thing to have.
Now that we have collected our data and pre-processed it we are ready to move on to the second part i.e. actually building the classifier. You can refer this post for the same.